

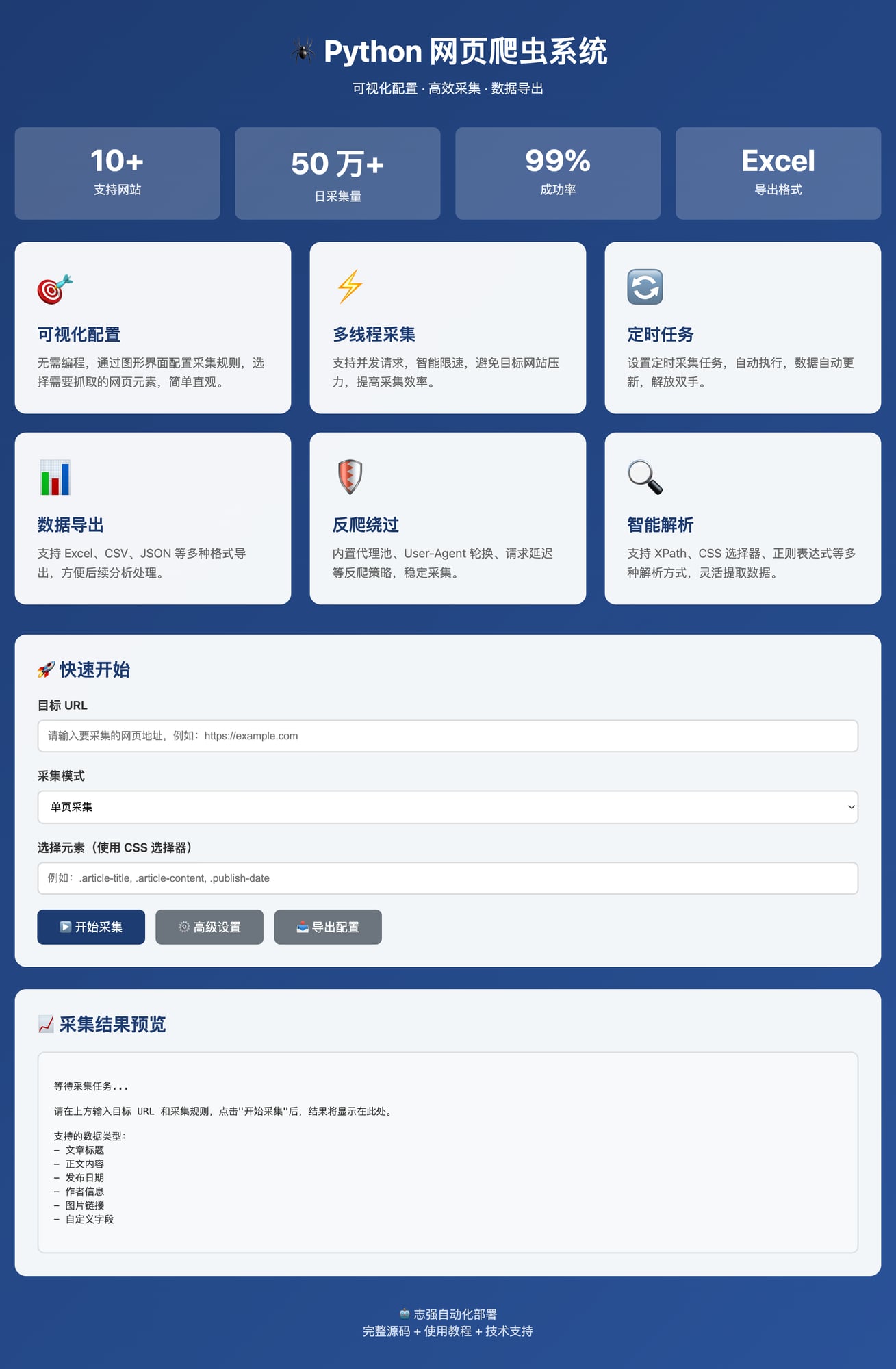
这是一款功能强大的 Python 网页爬虫系统,支持可视化配置、多线程采集、定时任务、数据导出等功能,无需编程即可快速配置采集规则!
🏠 网站名称:初晨源码之家
🔗 演示地址:http://crawler.ccyuanma.cn
🌟 核心功能
- ✅ 可视化配置 – 无需编程,图形界面配置采集规则
- ✅ 多线程采集 – 支持并发请求,智能限速,高效采集
- ✅ 定时任务 – 设置定时采集,自动执行,数据自动更新
- ✅ 数据导出 – 支持 Excel、CSV、JSON 等多种格式
- ✅ 反爬绕过 – 内置代理池、User-Agent 轮换、请求延迟
- ✅ 智能解析 – 支持 XPath、CSS 选择器、正则表达式
📸 界面展示
首页总览
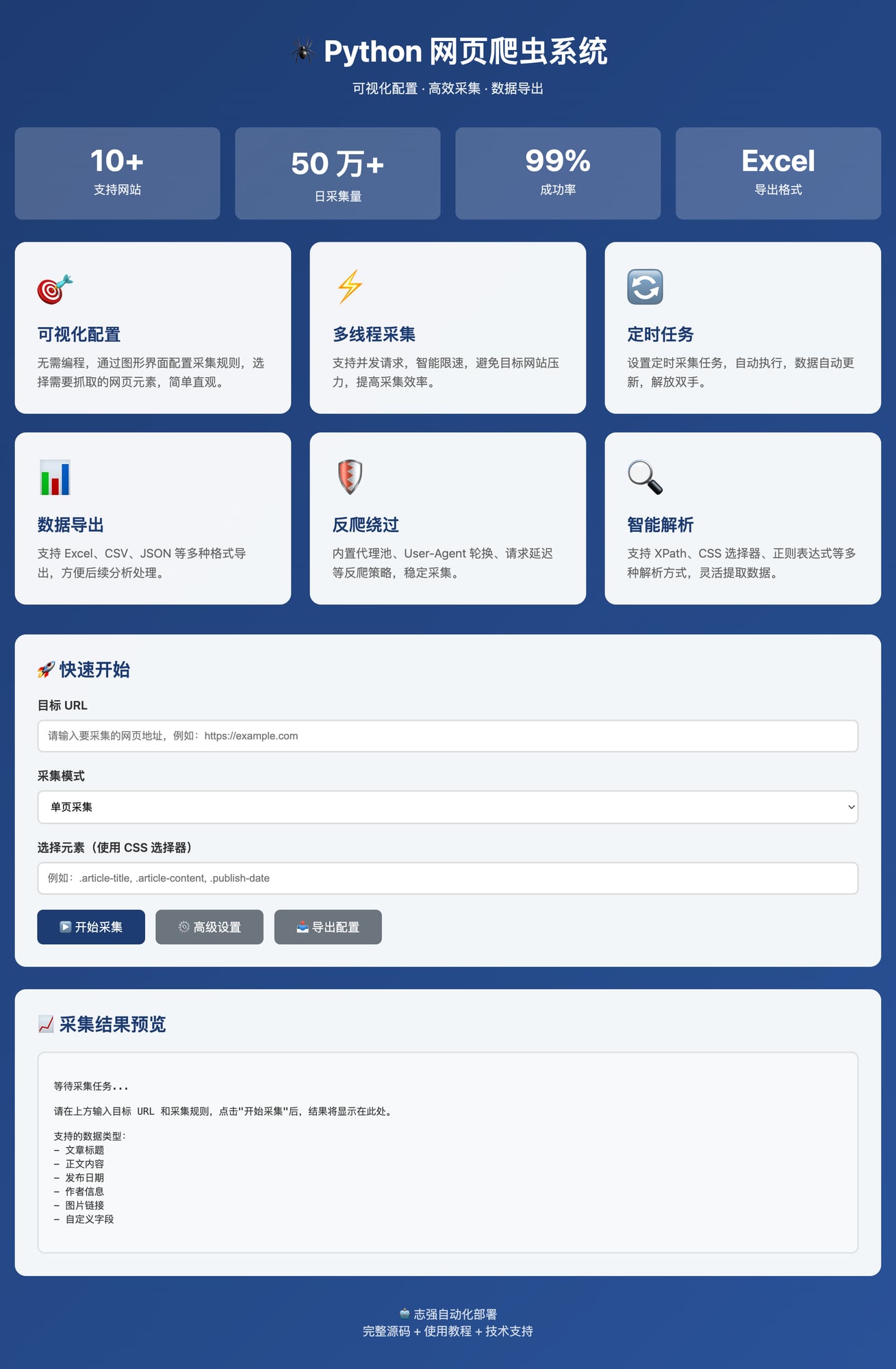
快速开始界面
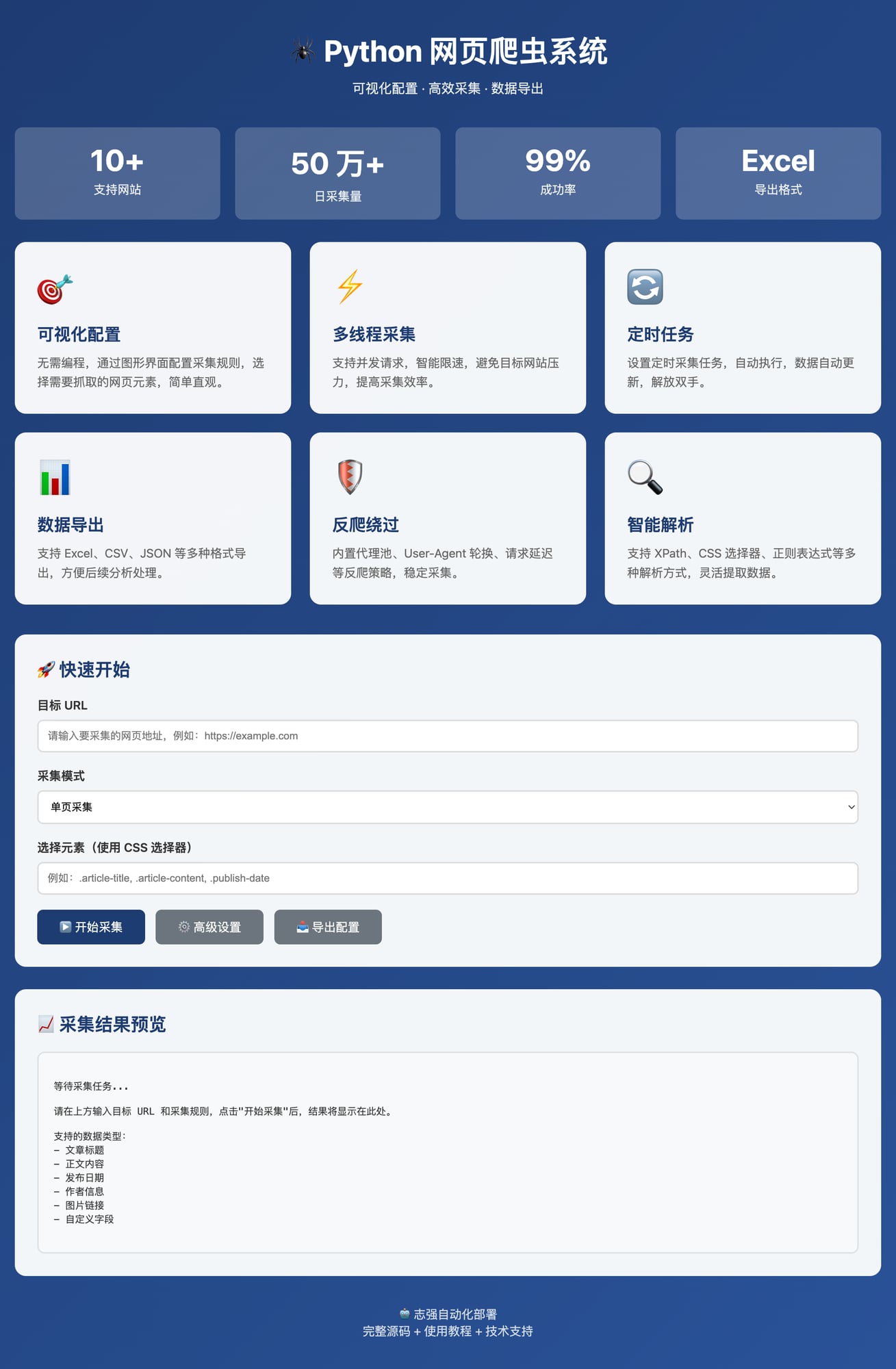
功能特性展示
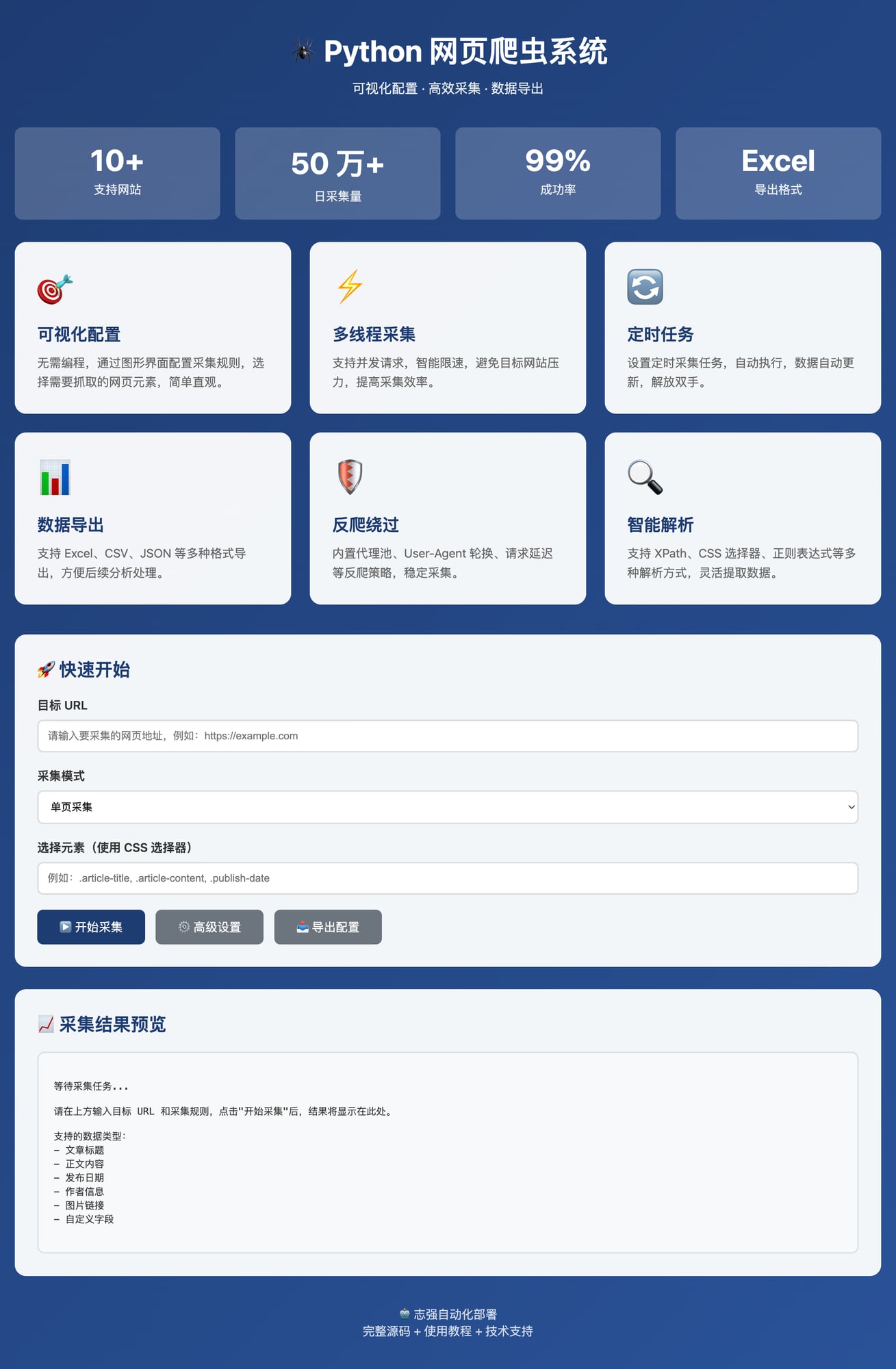
统计数据展示
顶部导航
🎨 界面设计
- 🎨 现代化蓝色渐变背景
- 💎 卡片式布局,信息清晰
- 📊 4 大统计数据直观展示
- 📱 响应式布局,支持移动端
- ⚡ 纯前端演示界面
🚀 部署教程
方式一:静态部署(推荐)
# 1. 上传到服务器
scp crawler.zip root@your-server:/www/wwwroot/your-domAIn/
# 2. 解压
cd /www/wwwroot/your-domain/
unzip crawler.zip
# 3. 配置 Nginx
server {
listen 80;
server_name your-domAIn.com;
root /www/wwwroot/your-domain/crawler;
index index.html;
}方式二:宝塔面板
1. 登录宝塔面板
2. 添加网站(填写域名)
3. 上传 crawler.zip 到网站目录
4. 解压即可访问
方式三:本地运行
# 直接双击打开 index.html
# 或使用 Python 快速启动
python3 -m http.server 8000
# 访问 http://localhost:8000📦 文件说明
| 文件 | 大小 | 说明 |
| index.html | 7 KB | 主页面(含所有功能) |
| crawler.zip | 2.6 KB | 完整源码包 |
🔧 技术栈
- 前端:HTML5 + CSS3 + JavaScript (原生)
- 样式:Flexbox + Grid 布局
- 特效:CSS3 动画 + 过渡效果
- 依赖:无(纯原生实现)
- 兼容:所有现代浏览器
💡 扩展建议
你可以在这个基础上扩展后端功能:
- 🐍 添加 Python 后端(Flask/FastAPI)
- 🕷️ 集成 Scrapy 或 BeautifulSoup 爬虫
- 💾 添加数据库存储(SQLite/MySQL)
- 📅 实现定时任务(Celery/APScheduler)
- 📊 添加数据可视化(Echarts/Chart.js)
- 🔐 添加用户登录和权限管理
📥 源码下载
本资源包含完整源码,下载后即可部署使用!
文件信息:
- 📦 文件格式:ZIP
- 💾 文件大小:2.6 KB
- 📄 包含文件:index.html
- 🔧 运行环境:任意 Web 服务器(Nginx/Apache)或本地直接打开
🎯 适用场景
- ✅ 数据采集和爬虫开发
- ✅ 竞品数据监控
- ✅ 舆情监控系统
- ✅ 价格追踪系统
- ✅ 学习爬虫开发实战
- ✅ 快速搭建数据采集平台
🏷️ 来源:初晨源码之家
部署时间:2026-03-09 02:43 | 演示:http://crawler.ccyuanma.cn
© 版权声明
THE END








暂无评论内容